HTTP Caching Guide
Introduction
Caching is hard. Let’s try and understand it a little better.
Note: some sections are purposefully brief. I’m not aiming to be a specification document.
Caching at multiple layers
Caching can occur at both a ‘client’ level and a ‘cache proxy’ level.
Consider the following request flow architecture diagram…
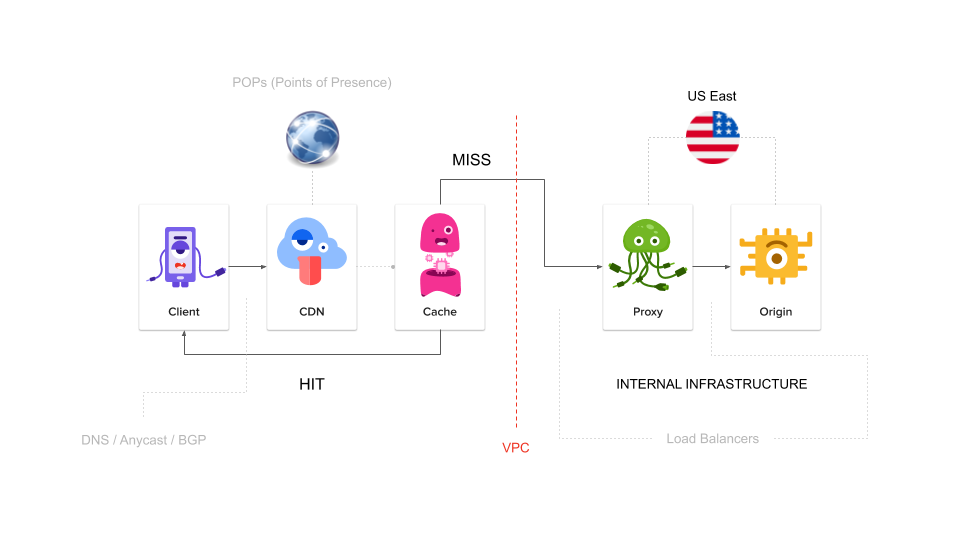
In the above diagram, the “CDN” is a ‘caching proxy’ and so caching can (and of course does) happen there.
The box that’s labelled “proxy” in the above diagram isn’t a caching proxy, it’s just a standard ‘reverse proxy’ that’s figuring out which (of many) ‘origins’ the request should be proxied onto (meaning: caching does not happen there).
We’re able to control caching for both ‘clients’ and ‘cache proxies’, using the following two HTTP response headers:
Cache-Control: tells a ‘client’ (e.g. web browser) how caching should be handled.Surrogate-Control: tells a ‘proxy’ (e.g. caching proxy/cdn) how caching should be handled.
In order to cache content efficiently we need to use a combination of the two headers.
Note:
Surrogate-Controlis typically stripped from the response, by a cache proxy, before the client receives it.
- Cache-Control Directives
- Surrogate-Control Directives
- Fastly CDN
- Disable Caching
- Serving Stale Content
- Cache Headers Example
- Conclusion
Cache-Control Directives
The Cache-Control cache response header has many directives you can configure, the following are some important ones to understand and will help you make an informed choice as to what values you set if you intend on controlling the caching of your content.
public: content can be cached by both client and proxy (implicit default).private: content can be cached by client, but not proxy (as content is unique to the user).max-age: determines how long (seconds) content is cached, after which requests will reach origin.s-maxage: used by ‘shared cache’ proxies and is equivalent toSurrogate-Control: max-age=<...>(except not stripped).must-revalidate: cached content can be served if TTL hasn’t expired, but do not serve ‘stale’ content under any circumstance.no-cache: cached content must revalidate on all requests (i.e. serve stale is fine, but only after consulting origin).no-store: prevents client or proxies from caching the content.no-transform: proxies aren’t allowed to modify content (e.g. don’t send compressed content if origin didn’t).
References: MDN:
Cache-Controland W3C Specification (see also: MDN: Caching).
client requests
One typically unmentioned feature of the Cache-Control HTTP header is that it can also be utilised at the client level for indicating to a cache what it will and wont accept.
This is an interesting perspective on caching that we rarely see.
In the case of Fastly CDN, they will ignore the Cache-Control header and its directives when provided as part of the client request.
Reference: RFC.
no-cache vs must-revalidate
A lot of the Cache-Control directives have subtle overlapping responsibilities, and no-cache/must-revalidate is one of the more confusing ones, so I’d like to take a moment to add some extra clarity…
With must-revalidate it’s suggesting that cached content must revalidate and not serve stale after the cached content’s max-age TTL has expired.
This is effectively saying “we have some content cached and its TTL is still valid so we’ll return that to you”, but the moment the max-age TTL expires it then changes to “sorry, we had cached content but it’s now stale and we’re not allowed to use it. we’ll go to the origin and grab fresh content for you.”
Unlike no-cache which is effectively saying “we have cached content, but before we release it to you we’re going to check with the origin that there isn’t a fresher version first”. It’s a way of enforcing a rigid ‘freshness’ plan.
Whenever using these (and other similar) directives, you need give consideration to what else needs to be in place to make them function efficiently. Specifically you need to be sure your origins are actually capable of handling revalidation (see ‘Serving Stale Content’ for more details), otherwise the behaviours might not work as intended or perform as well as you think they will.
Surrogate-Control Directives
For the Surrogate-Control cache response header you’ll mostly utilize the max-age directive along with the ‘extensions’ for serving stale content (e.g. stale-while-revalidate and stale-if-error).
There are some other directives defined in the W3C Specification, but it’s unclear how well those are supported by our primary CDN provider (Fastly) and so it’s best to avoid them unless you fully understand why you are setting them.
Fastly CDN
Fastly has some rules about the various caching response headers it respects and in what order this behaviour is applied. The following is a summary of these rules:
Surrogate-Controldetermines proxy caching behaviour (takes priority overCache-Control) †.Cache-Controldetermines client caching behaviour.Cache-Controldetermines both client/proxy caching behaviour if noSurrogate-Control†.Cache-Controldetermines both client/proxy caching behaviour if it includes bothmax-ageands-maxage.Expiresdetermines both client/proxy caching behaviour if noCache-ControlorSurrogate-Controlheaders.Expiresignored ifCache-Controlis also set (recommended to avoidExpires).Pragmais a legacy cache header only recommended if you need to support older HTTP/1.0 protocol.
† except when
Cache-Controlcontainsprivate.
It’s worth reiterating a segment of the above priority list which is that Cache-Control can include serving stale directives such as stale-while-revalidate and stale-if-error, but they are typically utilized with Surrogate-Control more than they are with Cache-Control. If Fastly receives no Surrogate-Control but it does get Cache-Control with those directives it will presume those are defined for its benefit.
Client devices (e.g. web browsers) can respect those stale directives, but it’s not very well supported currently (see MDN compatibility table).
If you’re interested in learning more about Fastly (inc. Varnish and VCL), then read my blog post on the topic.
Default TTLs
The CDN (Fastly) has some rules about how long it will cache content for.
Below is a (oversimplified †) summary of these rules.
- If your origin doesn’t set a cache response header, then cache content TTL will be 1hr.
- 1hr TTL is set by Fastly’s VCL boilerplate (applied by default).
- 1hr TTL can be overridden by your own custom VCL.
† Fastly has many factors it takes into account when deciding if an object stays in its cache (see: LRU).
Disable Caching
Depending on your requirements, when trying to disable caching it can be confusing to know which cache control directives to utilize due to the various permutations. Below is a Fastly recommended list of directives your origin can use for handling three common scenarios.
- Disable Client Caching (docs):
Cache-Control: no-store, must-revalidate - Disable Proxy Caching (docs):
Cache-Control: private - Disable ALL Caching (docs):
Cache-Control: no-cache, no-store, private, must-revalidate, max-age=0, max-stale=0, post-check=0, pre-check=0Pragma: no-cacheExpires: 0
Note: regarding the disabling of caching at the client level, I reached out to Fastly because of their suggested use of
must-revalidatewithno-store(which doesn’t make sense). They have since consulted with their resident RFC expert who confirmed this was redundant, and so expect their documentation to be updated to justno-store.It’s also worth mentioning that Fastly’s use of
post-checkandpre-checkis also redundant as per this old Microsoft article that states setting them to zero does not actually ‘do anything’!
Serving Stale Content
As you saw at the beginning of this post, we have a ‘reverse proxy’ that’s placed in front of our origin servers. This proxy will configure (as a default) cache settings that will result in stale versions of our origin’s cached content being served when the max-age TTL for that content has expired.
There are two distinct types of serving stale logic:
stale-while-revalidate: serve stale content while asynchronously checking for fresh content.stale-if-error: serve stale content if request to origin fails.
A key part of the stale-while-revalidate flow is for the origin to indicate when a particular resource has been ‘refreshed’ (i.e. a newer version is available). This is achieved by the origin providing either an ETag (entity tag) or a Last-Modified response header.
The ETag and Last-Modified response headers (sent from the origin) are used as values in a ‘conditional request’ made by the cache (client or proxy cache) to determine if the origin should send back either a full response or a smaller 304 Not Modified if the revalidated content hasn’t changed.
The benefit of a conditional request is that we’re able to reduce bandwidth whenever a 304 Not Modified is returned from the origin, because it will be sent with an empty response body (where as, of course, 200 OK will include the full response body).
There are many conditional headers, but the following are the most common when dealing with ETag/Last-Modified:
- ETag:
If-None-Match - Last-Modified:
If-Modified-Since
Reference: sequence diagrams demonstrating the various request flows.
If neither ETag nor Last-Modified is sent by the origin, then the cache will not be able to update the cache object. This means the object’s TTL (i.e. max-age) will still be expired, and other properties of the cache object will also not be updated, such as its ‘age’ (reset it back to zero once the content is refreshed), nor its ‘grace’ period (how long it will be able to serve that content stale for).
ETag or Last-Modified?
The official W3C specification provides ‘rules’ for when to use ETag vs Last-Modified. In summary…
the preferred behavior for an HTTP/1.1 origin server is to send both a strong entity tag and a Last-Modified value.
A good additional reference is MDN’s article on Cache Validation.
Revalidation TTL
One aspect of serving stale content that normally confuses people is how to determine the TTL for stale-while-revalidate. It would seem that determining a TTL for stale-if-error is fairly straight forward, in that you’ll just pick an arbitrarily long time period to serve stale, while the stale-while-revalidate directive isn’t as simple.
Consider the following diagram which highlights a typical request flow when using (for example) an ETag to handle the revalidation step:
Note: this diagram presumes the use of a CDN like Fastly which has specific behaviours, such as ‘request collapsing’ built-in.
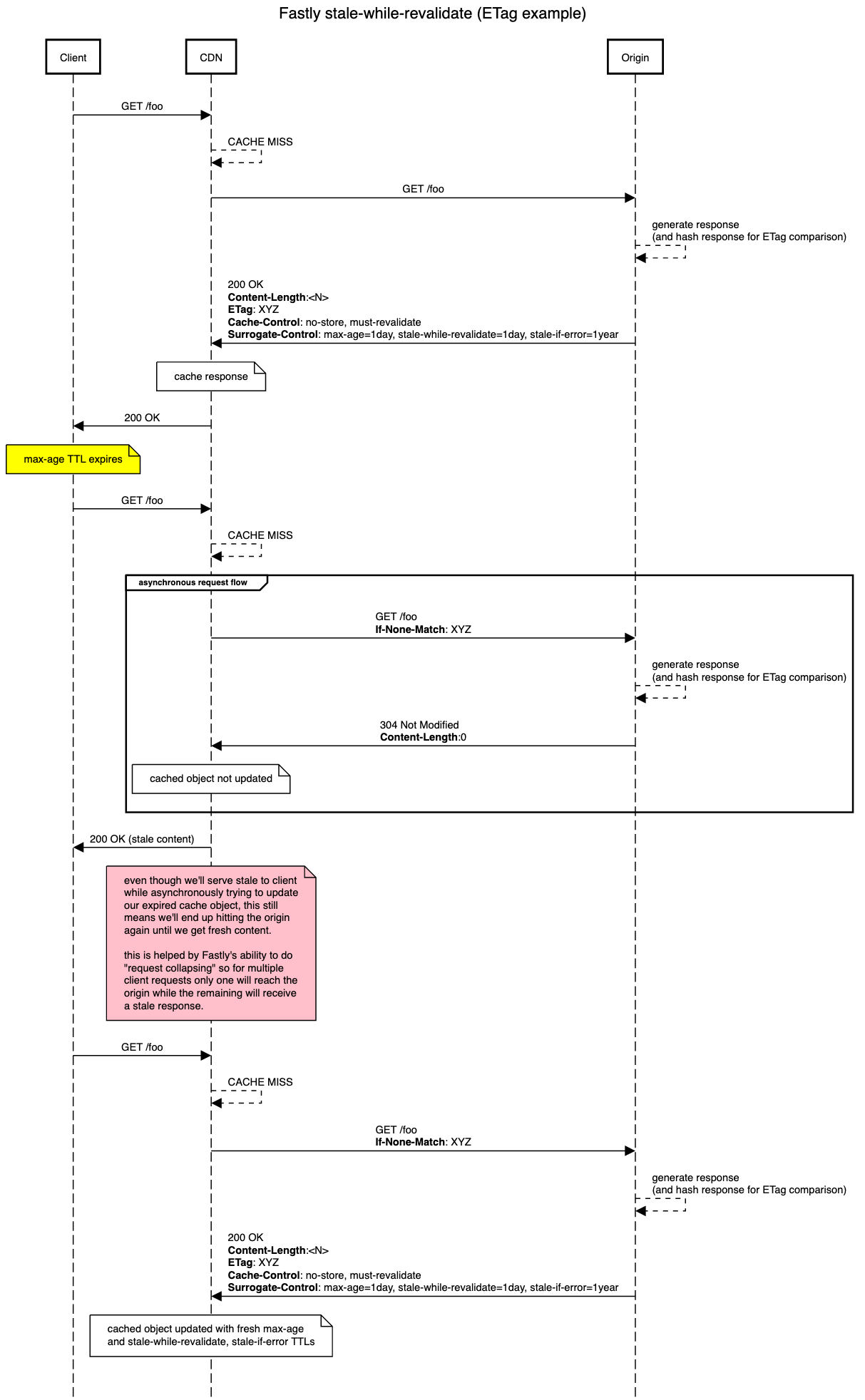
In this request flow we can see that although we’re successfully serving stale content when a cached object’s TTL has expired, this is still potentially going to result in multiple requests to the origin (rather than acting as a cache HIT) if we have an influx of requests for the same resource.
Now with that said, the ability to reach the origin (if we’re using Fastly at least, other CDN providers may differ) is only going to be on a datacenter by datacenter basis. The reason being, each cache node will perform request collapsing which will mitigate the damage of having to allow a request through to your origin.
With this in mind, having a large stale-while-revalidate TTL might not necessarily be a good idea because ultimately for that time period, if there is no updated version of the content, new client requests are going to be able to reach the origin.
Yes, it’s not going to be millions of requests (even if you’re a globally distributed brand), and Yes, having an empty response sent back from origin with the 304 Not Modified is better as far as bandwidth consumption is concerned, but the origin still has to spend time and resources constructing the response.
So depending on your origin and potentially the costs related to these types of requests it might be better to have a shorter stale-while-revalidate TTL so that it would expire more quickly.
This would then mean the request would go back to the origin sooner, in order to get a full response back to be re-cached, which would then result in future client requests actually getting a cache HIT and saving the origin from having to handle that extra unnecessary load.
On the ‘flip side’, I think the actual question needed to be asked is: “how important is it that you get fresh content as quickly as possible”?
The answer to that will firstly depend on whether we were using a CDN where purging content dynamically was not possible (specifically whenever fresh content was published by an origin). Fastly enables this dynamic purging by providing support for setting a Surrogate-Key HTTP response header.
So if we were in that situation where we couldn’t dynamically purge our CDN cache, and the freshness of our content was important then I would imagine we would set a longer stale-while-revalidate TTL in order to force the caching proxy to attempt to revalidate more often.
Otherwise, again if we were in that situation where we couldn’t dynamically purge our CDN cache and we had ended up setting a short stale-while-revalidate TTL, then that would mean we’d go back to origin and get a new max-age TTL set (which could be set to a very long value) and so we could end up with users getting a cache HIT for content which for all extensive purposes could very well be stale anyway but you would lose the opportunity to try and acquire fresh content via revalidation now.
If you’re using a CDN such as Fastly, you can utilize Surrogate-Key to purge your content dynamically whenever fresher versions have been published. Meaning, you could have a short revalidation TTL and if there was no fresh content within that time period you wouldn’t actually have to worry about going to origin and getting the same content back but now with a long max-age TTL, because you know you could dynamically trigger a cache MISS whenever your fresh content was published anyway.
Open Question: do you think
stale-while-revalidateshould contain a long or short TTL (and why)?
Strong and Weak Validators
As far as the actual setting of an ETag is concerned, this isn’t necessarily as straight forward as you might first imagine. For example, a typical approach is to use a hash function to generate a digest of the response body to verify the content has changed.
Of course there is the potential for the hash function to not be robust enough to avoid hash conflicts, but additionally there is a concept referred to as “validation” which needs to be considered (e.g. should the ETag be marked as being a “strong” validator or a “weak” validator).
These are things that you’ll need to consider when generating an ETag for a resource, and it’s recommended you read documentation on what constitutes a “strong” or “weak” validator.
Note: it’s important to realize that generating an
ETagand figuring out theLast-Modifieddate of a resource is outside the responsibility of a proxy, hence the proxy sat in front of our origins doesn’t set these headers even when they aren’t set by the origin.
In essence a strong ETag indicates that the resource’s content is the same with regards to both the response body and the response headers, whereas a weak ETag indicates that the two representations are semantically equivalent. It compares only the response body. Weak ETags are prefixed with W\ and thus can easily be distinguished between weak and strong.
Cache Headers Example
Let’s wrap up by considering a real-world example of cache headers and what they look like, and why.
The request flow architecture that I have at work takes the form of:
Client > CDN > Load Balancer(LB) > Proxy > LB > Proxy > LB > Origin
There are reasons for the multiple proxy layers in front of our origin servers, but I’m not going to dig into that here.
The proxy nearest the front of that list is acting as a gateway of sorts, and so if our origins fail to set any caching instructions, that proxy will add some defaults on their behalf.
This is all documented as service contracts, and so these origins are choosing to opt into those defaults, but they have full control over how their content is cached if they so choose to.
This proxy layer will by default tell the client to not cache your content, while indicating to any ‘caching proxies’ (e.g. Fastly CDN) that they should cache your content:
Cache-Control: no-storeSurrogate-Control: max-age=86400, stale-while-revalidate=60, stale-if-error=31536000
Note: values are in seconds, so
86400= 1 day,60= 1 minute,31536000= 1 year.
The reason for choosing to only cache content at the CDN rather than the client is because we have very granular control over our CDN cached content (thanks to our CDN provider, Fastly) and so its preferable, for our situation, to have complete control over the caching of our content rather than let a client’s browser determine what happens.
For example, if we didn’t do this and we allowed the client to cache our content in their own private caches, then it would mean if we had a request from our legal department to take down a piece of content, we wouldn’t be able to remove it from the client’s cache as that’s outside of our control.
Things can get a bit murky if there are proxies placed in front of our CDN (e.g. ISP proxies or maybe client is inside a local corporate network that runs caching proxies), but we set no-store which should tell clients/proxies to not cache. The reason this works with Fastly is because it doesn’t respect no-store (it sees that as a client cache directive), it instead respects private (which is more appropriate), and so that’s another way of us hopefully catching any unknown proxies in front of our CDN.
All of this leads us to the fact that when we purge our cache, we feel confident that we’re capable of successfully purging it from the internet as a whole.
Conclusion
Yes, caching is hard but it’s also not rocket science either. Take some time to read over the Cache-Control directives. Try to get comfortable with them.
It’s our responsibility as engineers building HTTP services to understand the platform we’re building services upon.
❤️
But before we wrap up... time (once again) for some self-promotion 🙊