Thread Safe Concurrency
2020.02.25 UPDATE: this post was written a long time ago and I realize now (upon reflection) that it dips hazardously in-and-out between various programming languages without really warning the user properly ahead of time.
The reason for using different languages was to highlight the fact that the various concurrency tools and mechanisms weren’t fully supported across languages.
Feel free to skip over these code examples if you like. The explanations that precede the examples should hopefully suffice.
But before we get into it... time for some self-promotion 🙊
Introduction
Concurrency is a difficult concept. Regardless of programming language or idiom that you use, the practice of programming a “thread-safe” application can be harder than you think.
There are two fundamental models of concurrency:
- Shared Memory
- Message Passing
In the first, we have concepts such as Threads, Locks and Mutexes. In the latter we have patterns such as Actors and CSP, which rely on the mantra of…
“don’t communicate by sharing memory; share memory by communicating”
Shared Memory
The following diagram is an extremely simplistic view of how CPUs, Processes and Threads interact but should help us to better understand why code can become NON thread-safe (as far as the “Shared Memory” model is concerned; we’ll see shortly that the “message passing” model side steps this issue):
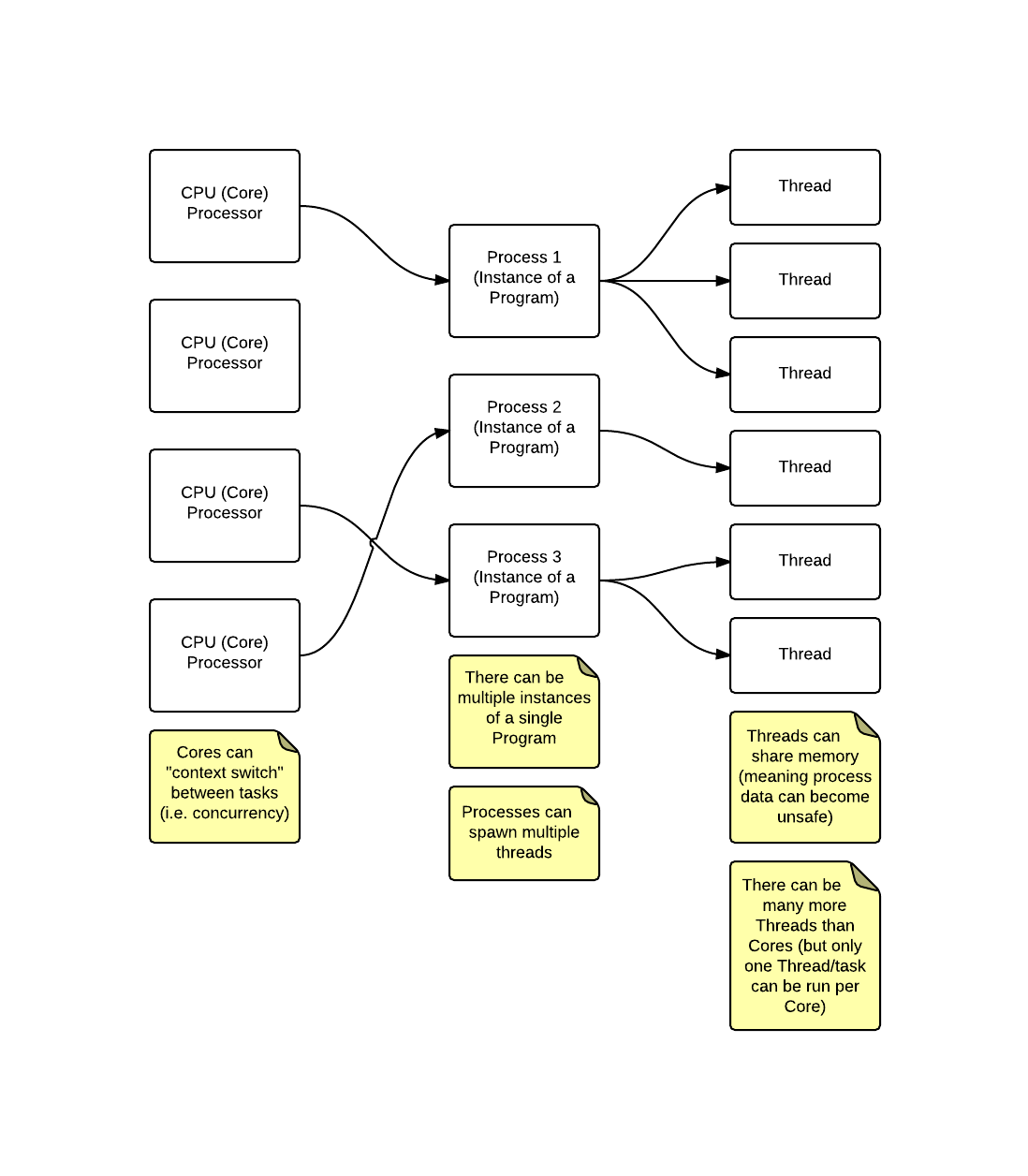
…for those of you who cannot see the image, effectively a process can spawn multiple threads and each thread belonging to a specific process shares the memory related to the process.
Meaning if your software process creates two threads, then both threads have access to the same memory space and thus can manipulate the same chunk of memory (and by memory, I’m specifically referring to data the application creates/has access to).
This means, if your software creates some mutable data (e.g. in Ruby this could look something like foo = "bar" - a foo variable that holds the String value bar) and you want to modify the value of the variable, then multiple threads could manipulate the value in an unexpected order and subsequently cause a difficult to locate bug.
Any time you create a new Thread and within that Thread you modify a mutable piece of data you should be concerned about how “thread-safe” that data is.
Note: if you’re also utilising immutable data structures (as found in more functional languages, but also languages such as Go where they “pass by value” rather than “pass by reference”) then this also makes code less prone to thread-safety concerns (but that’s a discussion for another day)
Message Passing
The message passing model relies on no data being shared, but rather communication between processes happening via either a message bus or by piping messages down a channel (depending on which style is implemented in your programming language of choice).
As well as avoiding the issue of data being shared, it also avoids the issue of trying to recover from failures (which thread/process is the correct one); which is a hard problem to reason about.
Various options
There are four main types of solutions to the problem of thread-safe concurrency:
- Mutexes/Semaphores
- Software Transactional Memory (STM)
- The “Actors” pattern
- Communicating Sequential Processes (CSP)
Let’s investigate each of these in turn:
Mutexes/Semaphores
We’ll be discussing specifically “mutexes” rather than “semaphores” (they have very similar purposes - in that they control access to specific data - although a mutex offers some additional guarantees).
When using a mutex, you can “lock” a piece of data so only that specific Thread has access to the data. When done manipulating the data you can “unlock” it, thus allowing another Thread to use a mutex to “lock” the data so it can make its own changes.
Let’s take a look at an example (in Ruby):
# imagine `data` is some shared state
def update
mutex = Mutex.new
Thread.new { mutex.synchronize { data += 1} }.join
end
Note: for the full Mutex API see http://www.ruby-doc.org/core-2.1.5/Mutex.html
This particular solution is the simplest of the three. BUT it doesn’t take into account any logic for handling unexpected changes to data (we’ll see what that means later on in the STM section).
Mutex vs Semaphore?
A semaphore is a construct which can be used to constrain or control access to a shared resource (typically this means access across multiple threads). Think of a semaphore as a more ‘generalized’ version of a mutex.
A mutex ensures a single thread only ever has access to a segment of your code (e.g. it guards the ‘critical section’ of a piece of code), where as a semaphore is concerned with ensuring that at most N threads can access your code.
Below is an example in golang:
// Package middleware provides wrapper functions around the http.Handler
// interface, allowing for an incoming HTTP request to be modified or analysed.
package middleware
import (
"net/http"
"github.com/example/internal/pkg/settings"
"golang.org/x/sync/semaphore"
)
// LimitConcurrency will reject any new connections that exceed the service's
// ability to continue functioning.
func LimitConcurrency(handler http.Handler, config *settings.Config) http.Handler {
s := semaphore.NewWeighted(int64(config.ConcurrencyLimit))
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
if !s.TryAcquire(1) {
http.Error(w, "TOO_MANY_CONCURRENT_CONNECTIONS", http.StatusServiceUnavailable)
return
}
defer func() {
s.Release(1)
}()
handler.ServeHTTP(w, r)
})
}
Notice how we have a similar API to a mutex (e.g. with a mutex you have to acquire a ’lock’ where as with a semaphore you have a number of ‘spaces’ the code is allowed to acquire). We attempt to ‘acquire’ one of the available semaphore spaces (e.g. when we created the semaphore we passed in a threshold of config.ConcurrencyLimit which could be set to a value of 100). In the case of the threshold being 100 it means we have 100 semaphore ‘spaces’ available before our code starts to reject incoming connections.
Atomic operations
Locks and mutexes allow operations to become atomic, meaning that the change happens “as a whole”. Meaning it becomes thread safe because another thread can’t accidentally read a piece of data/state/memory that is half done (e.g. += in the above Ruby example would not be thread safe without the Mutex because a thread could read the value of data inbetween the read and the assignment that += carries out).
STM
Software Transactional Memory is known as being an “optimistic” process. Compare this to the lock-synchronisation mechanism of a Mutex, which implies the onus of whether a write action will succeed, should be on the “writer” (i.e. the “writer” locks the data, writes the data, then releases the lock).
The STM on the other hand doesn’t care what happens in another Thread, it instead records all the changes in a log file and then just before it confirms the write (referred to as a “commit” in STM terminology) it verifies the data we’re modifying hasn’t changed, and if it hasn’t we go ahead and commit the change made by our Thread.
If a change has been made to the shared data source, then the transation will start over; but this time using the latest copy of the data we’re modifying (this can in some cases cause a deadlock to occur).
Because the STM retries transactions when they fail, we should ensure that code within a transaction is idempotent and side effect free. Otherwise if the code isn’t idempotent, then that code will be run again and might mean data is changed or recorded in ways you didn’t expect (e.g. a call to log some data within a transaction could be called multiple times!)
Note: the STM is best used for applications that have frequent reads and can allow for low to medium write collisions. If you expect lots of write collisions then it may be best to opt for another pattern, such as the Actors pattern discussed in the following section.
In the Clojure programming language you’ll also find that the STM facilitates “embedded transactions”, which allows for greater atomicity. What this means in pratice, is that if there is a transaction that contains a sub-transaction, then in some implementations of the STM a failed transaction won’t necessarily cause the sub-transaction to fail. But in Clojure it will. Meaning that it’s definitely an atomic operation (all or nothing).
Clojure example
The following example uses the Clojure programming language to implement a thead-safe modification via the STM (specifically the ensure function allows us to tell the STM what shared memory to watch for changes while our transaction is ongoing).
Quick Clojure Concurrency Detour
A quick detour before continuing onto the example code…
Clojure provides quite a few different mechanisms and functions for handling concurrency.
The three core mechanisms are:
atomagentref
A ref provides synchronised access to shared mutable state in a coordinated fashion (i.e. it uses the STM to ensure multiple references are coordinated before applying changes). Whereas an atom is similiar, but differs in that it works like a straight forward CAS (compare and swap) operation. So an atom is considered un-coordinated. An agent is the same as an atom with the exception that it can be run asynchronously.
Clojure’s atom provides a validator function (pass :validator argument followed by a validating function), which prevents invalid values being set; similar to a function’s pre/post assertion conditions. You are also able to “watch” atoms for state changes via add-watch.
Note: there is also
Vartype which is a mutable variable and is created via thedefform. A variable is “thread-local” meaning it isn’t shared across threads (whereasatom,agentandrefare all accessible across threads)
Now let’s consider the following functions:
ref-setalterensurecommute
All of these functions must be called from within a transaction (e.g. this is achieved by calling them from within a dosync block).
The first function ref-set allows you to change the value of a reference directly (i.e. specifying a value rather than using a function).
The second function alter applies a user specified function to the reference. The transaction itself will be retried if any reference written to within the transaction has changed outside of that transaction.
The third function ensure helps to resolve a problem that arises when using alter. The alter function only retries the transaction when references are written to; this means it doesn’t check references that are used within the transaction and haven’t been written to. We can work around this issue and ensure (no pun intended) that any reference used within the transaction - written to or just read - would cause the transaction to restart.
The fourth function commute increases concurrency for references that you want to monitor for changes but don’t really care for their consistency; when you’re really only interested in getting the latest value. It helps to increase the concurrency by running the function applied to commute at least twice (maybe more). This means if you have multiple threads running transactions then whichever transaction changes the value at the point of a commit wins (i.e. last-one-in-wins behavior).
OK, with that out of the way let’s now review the example code…
The requirement in the code is that the two bank accounts must have at least 1000 in total between them. If we try to remove an amount from either account which results in the total amount falling below 1000 then we should not complete that transaction:
(def current-account (ref 500))
(def savings-account (ref 600))
(defn withdraw [from constraint amount]
(dosync
(let [total (+ @from (ensure constraint))]
(Thread/sleep 1000) ; allows for a more visible context switch
(if (>= (- total amount) 1000)
(alter from - amount)
(println "Sorry, can't withdraw due to constraint violation")))))
(println "STATE BEFORE MODIFYING")
(println "Current Account balance is" @current-account)
(println "Savings Account balance is" @savings-account)
(println "Total balance is" (+ @current-account @savings-account))
(future (withdraw current-account savings-account 100))
(future (withdraw savings-account current-account 100))
(Thread/sleep 4000)
(println "STATE AFTER MODIFYING")
(println "Current Account balance is" @current-account)
(println "Savings Account balance is" @savings-account)
(println "Total balance is" (+ @current-account @savings-account))
The output of the above code could look like the following (but refer to the below note which explains why in some instances, because the transaction can fail and automatically retry, you could possibly see the failure message informing the user that the transaction failed even when it was successful):
STATE BEFORE MODIFYING
Current Account balance is 500
Savings Account balance is 600
Total balance is 1100
STATE AFTER MODIFYING
Current Account balance is 500
Savings Account balance is 500
Total balance is 1000
Note:
printlnis sending data to stdout (defined as a thread-local dynamic variable). This variable is binded to the current Thread by default (meaning values don’t cross over into other Threads).
A
futurecreates a new Thread, but the binding of stdout is inherited by thefuture’s parent process (i.e. anyprintlncalls within thewithdrawfunction - which runs in the parent process - can appear in thefuture’s thread); meaning the output sent byprintlndoesn’t necessarily reflect the correct state.
For example, even when the transaction completes successfully, you might see the failure message printed - at some point in stdout - because the failing message is coming from an earlier transaction that indeed failed. But after a retry the transaction passed and so the message you see in stdout doesn’t reflect the latest status of the application.
I would suggest that the
printlnmessage be moved outside of the transaction and that you add additional logic after the transaction code (this means after the transaction has completed; inc. retries) as a way to work around this issue with printing messages to stdout prematurely after a failed transaction.
I didn’t bother implementing this within my example, as it wasn’t essential to understanding the code.
JRuby example
If Clojure is a bit too much of a head spin (Lisp based languages can be quite confusing if you’re new to the syntax/concepts) then let’s see a similar example written in JRuby.
Note: because JRuby runs on the JVM, like Clojure, we take advantage of that fact and import Clojure’s STM functionality for us to utilise within our Ruby code
In the following example we have downloaded the Clojure runtime as a jar (from http://clojure.org/downloads) and are adding its location to the Java $CLASSPATH environment variable so when we try to java_import the relevant libraries, Java will be able to locate them.
Within our code you’ll see we’re using methods that correlate to what would be recognisable to Clojure’s environment: LockingTransaction.run_in_transaction, @balance.set and @balance.deref.
$CLASSPATH << "clojure-1.6.0/clojure-1.6.0.jar"
require "java"
java_import "clojure.lang.Ref"
java_import "clojure.lang.LockingTransaction"
class Account
attr_reader :name
def initialize(name, initial_balance)
@name = name
@balance = Ref.new initial_balance
end
def balance
@balance.deref
end
def deposit(amount)
LockingTransaction.run_in_transaction do
if amount > 0
@balance.set @balance.deref + amount
p "Deposited $#{amount} into account #{@name}"
else
raise "The amount must be greater than zero"
end
end
end
def withdraw(amount)
LockingTransaction.run_in_transaction do
if amount > 0 && @balance.deref >= amount
@balance.set @balance.deref - amount
else
raise "Can't withdraw $#{amount}; balance is $#{@balance.deref}"
end
end
end
end
def transfer(from, to, amount)
LockingTransaction.run_in_transaction do
to.deposit amount
from.withdraw amount
end
end
def transfer_and_print(from, to, amount)
begin
transfer from, to, amount
rescue StandardError => e
p "Transfer failed: #{e}"
end
p "Balance of 'from' account (#{from.name}) is $#{from.balance}"
p "Balance of 'to' account (#{to.name}) is $#{to.balance}"
end
account1 = Account.new 1, 2000
account2 = Account.new 2, 100
p "account1 balance is $#{account1.balance}"
p "account2 balance is $#{account2.balance}"
p "---"
transfer_and_print account1, account2, 500
p "---"
transfer_and_print account1, account2, 5000
The output of the above program is as follows… (notice that we see the deposit succeeds, but the transaction as a whole fails - i.e. the deposit is revoked - as we can’t withdraw the requested amount)
"account1 balance is $2000"
"account2 balance is $100"
"---"
"Deposited $500 into account 2"
"Balance of 'from' account (1) is $1500"
"Balance of 'to' account (2) is $600"
"---"
"Deposited $5000 into account 2"
"Transfer failed: Can't withdraw $5000; balance is $1500"
"Balance of 'from' account (1) is $1500"
"Balance of 'to' account (2) is $600"
Actors
The basic premise of the Actors pattern is built upon it being a form of “message bus”. The philosophy of the pattern is that everything is an Actor. An Actor receives messages and based on its state can determine whether it wants to handle the task defined in the message it has received, or to delegate the task off to other subordinates. An Actor can also create more Actors dynamically.
Each Actor is typically run in their own thread (using a Thread Pool implementation to allow for better resource management/allocation). This also helps to facilitate “isolated mutability”; i.e. mutable state is contained within the Actor but only that actor can modify the state (and as the Actor sits inside it’s own thread its mutable state is safe from other Actors).
Note: be very careful using the Actor pattern with languages that do not have native support for immutable data structures as you could open yourself up to hard to debug problems if your language allows mutability (e.g. Clojure supports immutability, but Ruby does not; Ruby does allow you to
freezean object, but that doesn’t include any nested structures). Much like how we’ve utilised Clojure’s STM in the above JRuby example, you can also import its immutable data structures. Although this won’t help you if you’re forced to use a non-JVM language such as MRI (which is the main Ruby interpreter written in C).
The use of messages allows communication to become asynchronous and loosely coupled from the rest of the system. But this can result in non-sequential message order (unless you have an Actor whose role is to ensure ordering via some form of Queue).
The Actor pattern has been made popular via Erlang and Scala (in the form of the Akka framework)
Note: Akka has bindings for other JVM based languages (Clojure, JRuby, Groovy): http://doc.akka.io/docs/akka/2.3.4/additional/language-bindings.html
I’ve yet to get around to writing any Scala code and so because Scala is the defacto example of the Akka framework I’ve decided to borrow an example from the official Akka site:
case class Greeting(who: String)
class GreetingActor extends Actor with ActorLogging {
def receive = {
case Greeting(who) ⇒ log.info("Hello " + who)
}
}
val system = ActorSystem("MySystem")
val greeter = system.actorOf(Props[GreetingActor], name = "greeter")
greeter ! Greeting("Charlie Parker")
Transactions and Actors?
Actors can also coordinate more safely by combining themselves via STM transactions. These are typically referred to as “transactors”. The benefits of wrapping messages within a transaction is that we eliminate synchronisation concerns (i.e. as changes within a transaction are purposely atomic).
Note: in Clojure, when sending an action to an agent from inside a transaction, the call is still non-blocking and yet it also still abides by the STM rules (i.e. the action is held until the transaction commits)
Actors in Clojure
Clojure does not support Actors, although it does have a mechanism known as “agents”. An agent provides access to shared mutable state, but does so asynchronously (much like an Actor). Where an Actor receives a “message”, an agent accepts an action.
Note: Actors and Agents have some surface similarities, but ultimately are different beasts. Actors “encapsulates” state and provides no means to access it from the outside. Whereas Agents contain a single value that can be retrieved and manipulated (via
sendorsend-off- see below for details). Actors also encapsulate behaviour, whereas an Agent is provided the function that affects its value. Actors can be distributed, whereas Agents cannot
Whereas the STM provides coordinated access to data (i.e. atomic - it verifies that there are no changes to shared data that has been written to; otherwise it’ll cause the entire transaction to fail). Agents are independent; meaning that actions run concurrently (the call to action returns immediately), but the actions are executed sequentially via a separate thread. So where a transaction is a synchronous operation, an action handled by an agent is asynchronous.
In Clojure, agents are transaction aware (whereas atoms are not) and the ! at end of function name is an indicator of this: swap! (not coordinated) vs send.
Note: the agent API in Clojure provides two methods:
send-offandsend. The former creates a new thread specifically for that agent; whereas the latter selects a thread from a pre-defined thread pool. The problem withsendis that agents fight for an available thread and so if your action does blocking I/O then you’ll delay other agents from working (and thus reducing the extra concurrency benefits of using a thread pool)
Once the agent’s state is changed, the next action is applied to the agent (now using the latest state it points to).
Differences between Agents and Erlang Actors
There is one distinctive difference between Erlang’s Actor and Clojure’s Agent, which is that an Agents “action” doesn’t block additional value request calls like an Erlang “message”. This is demonstrated in the following image, but in summary: requests to an Actor are blocked until a response to the previous message can be provided; whereas Clojure Agents allow multiple @deref calls to be made and processed:

Note: in the above image we have two simultaneous requests to “increment” the value held by the Actor/Agent. One can succeed, the other goes onto a queue and is applied after the first call finishes.
Limitations
The Actor pattern does have some limitations:
- Languages that do not enforce immutability are more prone to thread safety bugs
- Actors can be left starving if a dependant Actor fails (they’ll be left waiting for a message that will never arrive)
- This means we should program defensively and raise exceptions to the waiting Actors
- The Actors pattern does not prevent a dead/livelock scenario (two Actors waiting on each other for messages)
- Again, we should program defensively by using timeouts to break a livelock
- Actors can only handle one message at a time, meaning we should be careful to not cause delays for messages that are only trying to “read” a value from inside the Actor
- The Actor pattern works best when problems can be divided into sections that do not rely on each other
- i.e. communication can be sporadic. If frequent interaction is needed or each section has a dependency on each other to coordinate the task then choose an alternative combination of concurrency models
CSP
Communicating Sequential Processes is an alternative mechanism for expressing concurrency, which has been popularized by recent languages Clojure and Go. It also is based on the idea of message passing, similar to the Actor pattern.
Some of the fundamental differences between this and the Actor pattern are:
- Messages are sequential
- Communication is synchronous
- Communication happens via defined “channels”
- Processes are anonymous
- i.e. Actors know who to communicate with
- Whereas Channels are pipes with messages going in and listeners the other end
You also have the option of applying other patterns such as multiplexing multiple channels down into one, think “fan-in”, which can help in certain scenarios where you want to accept lots of messages comming in (the reverse is also possible, i.e. “fan-out”).
Picking one model over another (Actor vs CSP) will be determined by the level of complexity you feel is inherently added by either solution and/or model your language of choice supports.
The following is an extremely simple demonstration of the CSP/channel model written in Go (there is a channel which accepts an infinite number of messages; and our main function will take the messages from the channel as they become available):
package main
import (
"fmt"
"math/rand"
"time"
)
func main() {
c := createChannel("hello", 5)
for i := range c {
fmt.Printf("You say: %q\n", i)
}
fmt.Println("I'm done.")
}
func createChannel(msg string, size int) <-chan string {
c := make(chan string, size)
go func() {
for i := 1; i <= size; i++ {
c <- fmt.Sprintf("%s %d", msg, i)
time.Sleep(time.Duration(rand.Intn(1e3)) * time.Millisecond)
}
close(c)
}()
return c
}
Again, it’s important to realise that Channels are synchronous and can block/cause deadlocks. In Go you can implement a timeout as a way of avoiding deadlocks. I’m not currently sure if Clojure has a similar work-around built into the language or whether you have to manually implement that yourself.
Threads
Threads are prevalent across both the “shared memory” and “message passing” models. The discussion of how many threads to create is an important one and depends on the type of tasks your application is expected to handle: CPU bound or I/O bound. In the following sections we’ll cover this topic, as well as describing an algorithm for calculating this.
What is CPU bound vs I/O bound?
Note: the following is credited to yaoyao.codes.
- CPU bound: the rate at which a process progresses is limited by the speed of the CPU.
- I/O bound: the rate at which a process progresses is limited by the speed of the I/O subsystem.
This means a task that performs calculations on a small set of numbers, for example multiplying small matrices, is likely to be CPU bound. While a task that processes data from disk, for example, counting the number of lines in a file is likely to be I/O bound.
A program is CPU bound if it would go faster if the CPU were faster.
A program is I/O bound if it would go faster if the I/O subsystem was faster.
The following is an explanation from “Essentials of Computer Organization and Architecture”…
Input and output (I/O) devices allow us to communicate with the computer system. I/O is the transfer of data between primary memory and various I/O peripherals. These devices are not connected directly to the CPU. Instead, there is an interface that handles the data transfers. This interface converts the system bus signals to and from a format that is acceptable to the given device. The CPU communicates to these external devices via I/O registers.
See also the following image that demonstrates how a CPU will allow interruptions for I/O based signals (source):
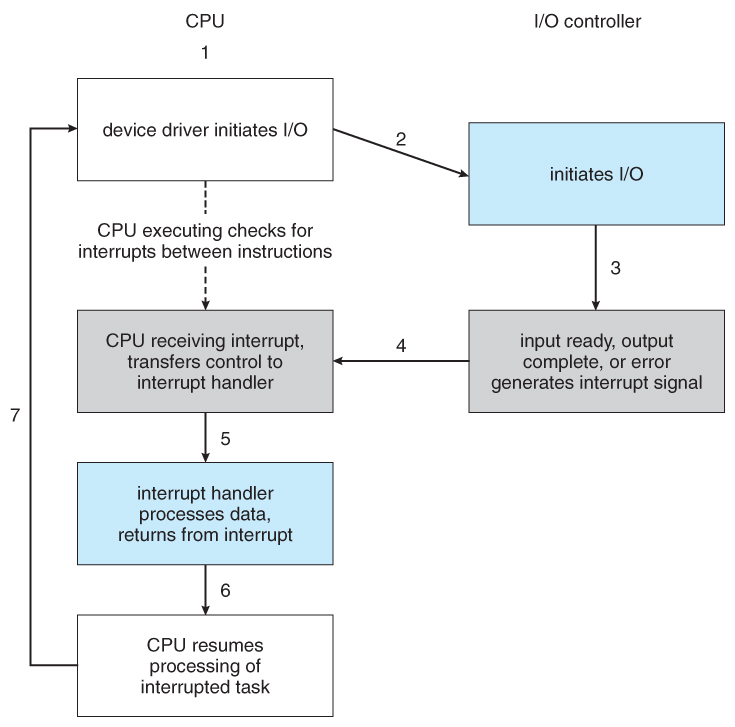
A CPU/Processor can contain one or more cores. For example, a quad core processor that runs at speed of 3GHz will have 4 cores running at that speed.
I/O, whether a file system interaction or a network request - e.g. HTTP, TCP or Socket based - can block other processes; and so if the application is designed to work concurrently (e.g. there are other threads the CPU can jump to in the mean time) then the current thread will be left to finish and another thread will be picked up instead (this is how concurrency works - the CPU interleaves between threads - this should also clarify how concurrency is not the same thing as paralleism).
For computational intensive operations you’ll want the number of threads to be equal to the number of cores available.
For I/O intensive operations you’ll want more threads than available cores. This is because (as explained above) the CPU/Processor will “context switch” to another thread when the current thread is blocked (hence it is better to have more threads than cores for I/O).
Calculating the number of Threads
To calculate how many more threads than cores you’ll need for an intensive set of I/O operations, use the following algorithm:
Number of Threads = Number of Available Cores / (1 - Blocking Coefficient)
Note: the blocking coefficient (coefficient being a fancy word that means: a value used as a multiplier) is different depending on the operation. For a computational operation it is 0, whereas a fully blocking operation it is 1.
An example of a blocking coefficient would be: 0.9 - which means a task blocks 90% (0.9) of the time & works only 10% (0.1) of the time. Meaning, if you had 2 cores then you’d want 20 threads.
2 / (1 - 0.9) = 20
Even workload distribution
If you have two cores and a very large queue of messages to process, then your initial thought would maybe be to split the queue (i.e. the tasks) into two. This would mean you could have two threads running (i.e. utilising both cores); the first thread processing the first queue data and the second thread handling the other half of the queue data.
The problem with this solution is that is doesn’t necessarily guarantee even distribution of the tasks across your available cores. If our queue data consisted of a computational task such as calculating prime numbers then the first half of the queue would take a lot less time to process because the smaller prime numbers would take less time to calculate than the other queue (which if evenly split in two would mean the other queue would have the much larger prime numbers to calculate).
This means one core will be sitting idle while the other core is still processing data.
What would be better is to have more parts than threads/cores. So if one “part” finishes more quickly than expected, then another part can be picked up. Simply diving our tasks into two parts means one core will likely be sitting idle for longer than the other core. But if we divide our tasks into more granular parts, then we can aim to utilise as much of each core as possible.
Conclusion
As mentioned at the start of this post: solving the problem of thread-safe concurrency isn’t necessarily as straight forward as you would have hoped (if you’re new to the concepts). Throw in distributed systems and the problem is conflated even further.
But with that being said, we can clearly see there are quite a few different options available to us already - albeit with differing levels of complexity depending on the problem we’re trying to solve. This is a good thing because you shouldn’t always reach for a more complex solution if it’s not necessary. If the problem is a small one and a simple mutex resolves it then maybe that’s OK. Don’t over engineer your system.
But before we wrap up... time (once again) for some self-promotion 🙊