OpsBot: Operations Slackbot
So this post is a long time coming. It has been pushed to the forefront by the fact that BuzzFeed recently held its annual ‘Hack Week’, and riding on the wind of a massive success I’ve had with my hack project this past week…
“Mark has casually saved the company $60k a year by letting us break away from a commercial dependency without losing any features!” – BuzzFeed UK Newsletter
…I’ve decided to revisit last years hack week project: OpsBot, which is a Slackbot for operational tasks.
Note: for those interested, the presentation slides for my 2018 hack can be found here.
What does OpsBot do?
- Creates standardized incident channels.
- Auto-invite users to incident channel based on emoji reactions.
- Looks up service runbooks.
How do you use OpsBot?
/incident <name> [visibility] [reporter]/runbook <service>
Let’s break down the arguments provided to each command:
name(required):
hyphenated name of the incident, e.g.Service-Foo-5xxvisibility(optional):
whether the channel should be public or privatereporter(optional; has a default channel):
name of channel where incident was first reportedservice(required):
searches our company Google Drive for specified runbook
Incident Example
Imagine I’ve noticed something bad has happened. I’ll go to the appropriate Slack channel and report it.
At that point people who are interested in the incident will use an 👀 emoji (we support various types) to indicate their interest in being auto-invited to a new incident channel (if one is to be created).
The following image demonstrates what that might look like…
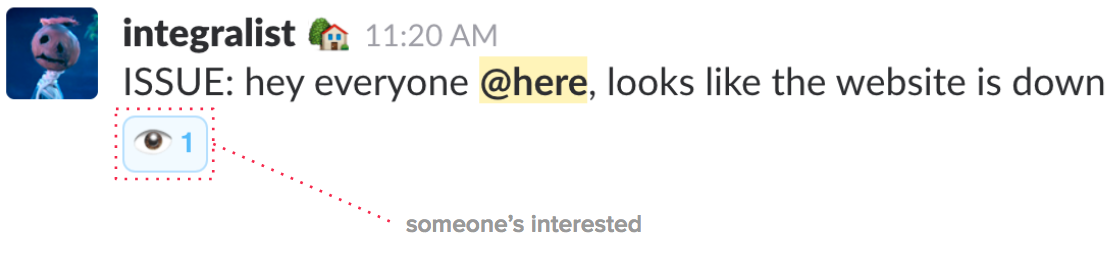
Note: we have automated notifications sent to specific monitoring slack channels, and so people can also use the emoji reaction on those messages.
Now imagine this incident has been triaged and yes it is indeed a problem. We’ll need to spin up an incident channel so we can focus discussions and get a resolution in place.
It’s at that point someone runs the command: /incident bf4life (or whatever you want to name the incident 😉) and we’ll see the following…

Notice that we automatically prefix the given incident name with the current date, so it’s easier to go back and review/identify past incidents.
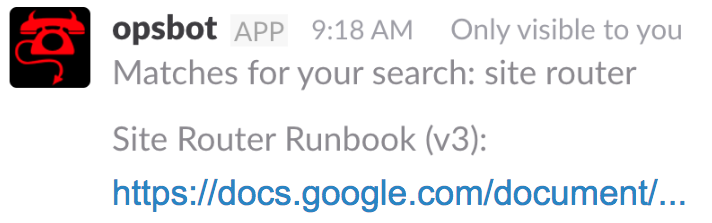
If we’re dealing with a service that we’re unfamiliar with, then we might also want to look at the runbook(†) for that service.
† a runbook is a compilation of routine procedures and operations that the system administrator or operator carries out – Wikipedia
This is when someone runs the command: /runbook site router (or whatever the affected service is) and we’ll see the following…
How does OpsBot work?
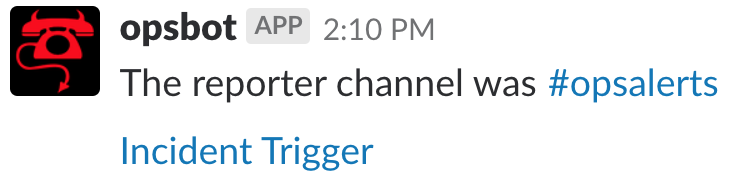
When creating an incident channel, OpsBot will link back to the channel that reported the incident as well as linking to the specific notification in that channel.
This works because OpsBot’s logic is trying to match one of two possible patterns within the message’s body:
- The phrase
ISSUE:begins the message (see example from earlier ☝️). - The message is identified as a automated NAGIOS
CRITICALnotification.
If the message is identified as an ‘incident trigger’ then that’s what we link to within the incident channel…
What did we learn?
- Have a pre-hack document with feature specifications in place.
- Slackbots are fun to create.
- The Google API was
kinda trickya PITA.
What could we improve?
Two issues cropped up fairly early on in the design:
- Identify who not to auto-invite to a private incident.
- Identify better ’nagios incident message’ grouping logic.
The first issue is an awkward one because we can’t necessarily stop people from accessing a private incident channel if they’ve gone into a public slack channel and used the emoji reaction on a particular incident.
That being said, we very rarely have to create private incident channels. That’s only when an incident relates to some serious security vulnerability, and nearly all the time those types of issues are raised via HackerOne and dealt with outside of typical monitoring notifications (like 5xx’s).
The second incident occurs when people add an emoji to a NAGIOS automated notification but then a repeat notification message is sent later. In this scenario a message pings to say there is an issue, people add the emoji reaction but later on (before an incident channel has been created) an updated NAGIOS error notification is sent.
Now when we create the incident channel, it’ll look for the first NAGIOS warning that matches and it’ll find no emoji reactions, so it won’t auto-invite people to the incident channel.
Although this isn’t the end of the world as people can still see the incident channel link generated (if it’s a public channel) and click on that to access the incident channel.
What else could OpsBot do?
OpsBot has the potential to do lots of things, it just depends on your needs and use cases.
For us, a few things we planned to do but never quite got round to was…
- A
/postmortemcommand for automatically creating our incident ‘Post Mortem’ documents. - A
/servicecommand for looking up the on-call team leads for that service(†). - Add runbook info to our deployment platform so OpsBot can pull it in auto-magically.
- A damn good refactor and some tests! (this was a ‘hack’ after all).
† this might materialise into another project we have for improving team relations called
#WhoWhatWhy(coming soon).
So that’s OpsBot. If you’re interested, the presentation slides for the OpsBot hack can be found here
But before we wrap up... time (once again) for some self-promotion 🙊